
أدوات الذكاء الاصطناعي القانونية تُظهر وعوداً واعدة في دراسة مرجعية فريدة من نوعها: هارفي وكو كونسيل يتصدران القائمة!
هل لا تزال مترددًا بشأن ما إذا كانت الذكاء الاصطناعي التوليدي يمكن أن تقوم بعمل المحامين البشريين؟ إذا كان الأمر كذلك، أود أن أشجعك على قراءة هذه الدراسة الجديدة.
نشرت هذه الدراسة التي تعد الأولى من نوعها أمس، وقد قيمت أداء أربعة أدوات قانونية تعتمد على الذكاء الاصطناعي عبر سبع مهام قانونية أساسية. في العديد من الحالات، وجدت الدراسة أن أدوات الذكاء الاصطناعي يمكن أن تؤدي بمستوى يساوي أو يتجاوز مستوى المحامين البشريين، مع تقديم أوقات استجابة أسرع بشكل ملحوظ.
يمثل تقرير Vals Legal AI (VLAIR) أول محاولة منهجية لتقييم أدوات الذكاء الاصطناعي القانونية بشكل مستقل مقارنة بمجموعة تحكم من المحامين، باستخدام مهام مستمدة من شركات Am Law 100.
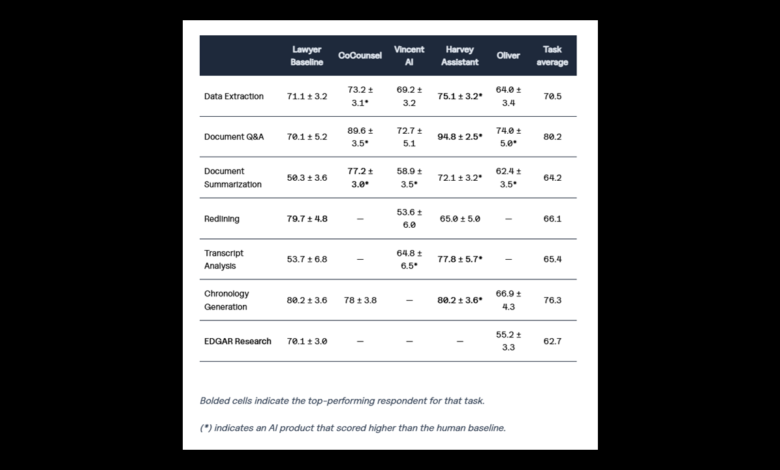
تم تقييم أدوات الذكاء الاصطناعي من أربعة مزودين — هارفي (Harvey)، وتومسون رويترز (CoCounsel)، وvLex (Vincent AI)، وVecflow (Oliver) — في مهام تشمل استخراج الوثائق، والأسئلة والأجوبة حول الوثائق، والتلخيص، وتحرير النصوص باللون الأحمر، وتحليل النصوص المنقولة، وإنشاء التسلسل الزمني، وبحث EDGAR.
شاركت LexisNexis في البداية في عملية التقييم ولكن بعد كتابة التقرير قررت الانسحاب من جميع المهام التي شاركت فيها باستثناء البحث القانوني. سيتم نشر نتائج تقييم البحث القانوني في تقرير منفصل.
النتائج الرئيسية
برز مساعد هارفي كالأداء المتميز حيث حقق أعلى الدرجات في خمس من المهام الست التي شارك فيها بما في ذلك معدل دقة مثير للإعجاب بلغ 94.8% للأسئلة والأجوبة حول الوثائق. تجاوز أداء هارفي أداء المحامين في أربع مهام وحقق نفس المستوى الأساسي في إنشاء التسلسل الزمني.
(يمكن لكل مزود اختيار المهارات التي يرغبون بالمشاركة فيها.)
“تستفيد منصة هارفي من نماذج لتقديم مساعدة عالية الجودة وموثوقة للمهنيين القانونيين”، قال التقرير. “تعتمد هارفي على عدة نماذج LLM ونماذج أخرى بما في ذلك نماذج مخصصة تم تدريبها على العمليات والبيانات القانونية بالتعاون مع OpenAI ، حيث تتضمن كل استفسارات النظام بين 30 إلى 1500 مكالمة نموذج.”
كان CoCounsel من تومسون رويترز هو المزود الوحيد الآخر الذي حصلت أداته على درجة عالية – 77.2% للتلخيص الوثائقي - وكان دائمًا ضمن الأدوات ذات الأداء العالي عبر جميع المهام الأربعة التي شاركت فيها ، مع درجات تتراوح بين 73.2% إلى 89.6%.
تفوقت مجموعة التحكم الخاصة بالمحامين (النتائج الناتجة عن مجموعة التحكم للمحامين) على أدوات الذكاء الاصطناعي في مهمتين – بحث EDGAR (70.1%) وتحرير النصوص باللون الأحمر (79.7%) مما يشير إلى أن هذه المجالات قد تبقى أفضل للقيام بها بواسطة البشر حتى الآن على الأقل. تجاوزت الأدوات المعتمدة على الذكاء الاصطناعي مجتمعة مجموعة التحكم الخاصة بالمحامي فيما يتعلق بتحليل الوثائق واسترجاع المعلومات ومهام استخراج البيانات.
ربما ليس مفاجئًا ، وجدت الدراسة فرقًا كبيرًا جدًا بين أوقات الاستجابة بين الذكاء الاصطناعي والبشر . وجد التقرير أن أدوات الذكاء الإصطناعى كانت “أسرع بست مرات عن أقل محامي وأسرع بـ80 مرة عند أقصى حد” مما يجعل قضية قوية لأدوات الذكاء الإصطناعى كمحفزات للكفاءة فى سير العمل القانونى .
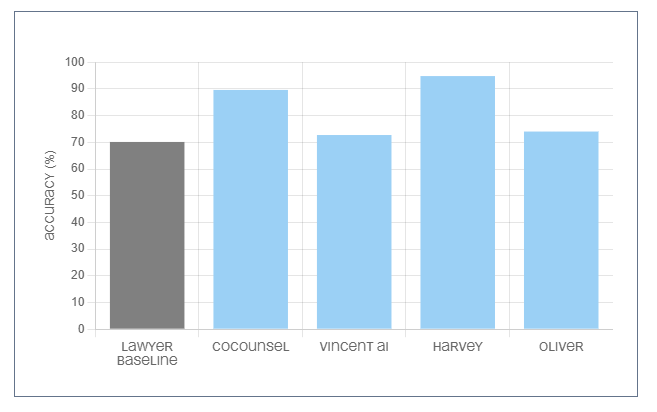
أسئلة وأجوبة حول الوثائق حققت أعلى الدرجات مقارنة بأي مهمة أخرى ضمن الدراسة ، مما أدى بالتقرير إلى الاستنتاج بأنها مهمة يجب أن يجد المحامون قيمة كبيرة عند استخدامهم للذكاء الإصطناعى التوليدي .
أداء محدد لكل مزود
< p > كان مساعد هارفي هو الأسرع نموًا كأداة تقنية قانونية حيث جمع أكثرمن $200 مليون وحصل علي وضع يونيكور منذ تأسيسه عام2022, اختار المشاركة بأكثر عدد ممكنمن المهامات مقارنة بأي مزود آخر وحصل علي أعلي الدرجات فِي الأسئلة والأجوبة حول الوثائق واستخراج المستندات وتحليل النصوص المنقولة وإنشاء التسلسل الزمني.< / p >< p > “حقق مساعد هارفي إما نفس أو تفوق علي مجموعة التحكم للمحامي فِي خمس مهامات كما تفوق علي باقي الأدوات المعتمدة عَلى ذكاءِ اصطناعِي فِي أربع مهامات تم تقييمها,” قال التقرير.”كما حصل مساعد هارفى أيضًا عَلَى اثنين مِن الثلاثة درجات الأعلى عبر جميع المهامات المُقيّمة فِي الدراسَة, لأسئلة وأجوبة حول وثيقة(94,8%) وإنشاء تسلسل زمني(80,2%- مطابقة لمستوى المجموعة الأساسية).”
< p > CoCounsel2.O مِن تومسون رويترز قُدم لأربع مِن المهمات وعادةً ما قدم أداءً جيداً ,وجدت الدراسَة , محققاً متوسط درجة قدره79,5 % عبر الأربع مهمات المُقيّمة – وهو أعلى متوسط درجة فِي الدراسَة . لقد برعت خصوصا فِي الأسئلة والأجوبة المتعلقة بالوثائق(89,6 %) والتلخيص(77,2%).
< p >شارك Vincent AI مِن vLex فِي ست مهمات – ثاني أكبر عدد بعد Harvey – مع درجات تتراوح بين53,6 %إلى72,7 %, متفوقا عَلَى مستوى المجموعة الأساسية للمحامي فيما يتعلق بأسئلة وأجوبة وثيقة والتلخيص وتحليل النصوص المنقولة.< / P >
< P >قال التقرير إن تصميم Vincent AI جدير بالملاحظة بشكل خاص بسبب قدرته عَلَى استنتاج الفرعية المناسبة لتنفيذها بناءً عَلَى سؤال المستخدم وأن الإجابات المقدمة كانت “شاملة بشكل مثير للإعجاب”.
< P >بشكل غريب(كما اعتقدت), أثنى التقرير علَى Vincent AI لرفضه الإجابة عن الأسئلة عندما لم يكن لديه بيانات كافية للإجابة بدلاً مِن إعطاء إجابة غير دقيقة ولكن ذكر أيضا ان تلك الرفض قد أثر سلبيا علَي نتائجه.< /P >
< P >وصف Oliver الذي صدر العام الماضي مِن شركة Vecflow بأنه “أفضل أداة ذكائية” خلال المهمة الصعبة المتعلقة ببحث EDGAR . يبدو أنه أمر مُسلّم به لأنه الأداة الوحيدة القادرة علَى المشاركة بتلك المهمة وسجل55,2 %مقابل70,.1%. < /P >
< P >< strong >< h4 >< Methodology >< The study was developed in partnership with Legaltech Hub and a consortium of law firms including Reed Smith,Fisher Phillips,McDermott Will & Emery,and Ogletree Deakins along with four anonymous firms.The consortium created a dataset of over500 samples reflecting real-world legal tasks.
Vals AId eveloped an automated evaluation framework to provide consistent assessment across tasks.The study notes that the lawyer control group was “blind” — participating lawyers were unaware they were part of a benchmarking study and received assignments formatted as typical client requests.
Tara Waters was Vals AIs project lead for the study.
< The report indicates this benchmark is the first iteration of what its says will be a regular evaluation of legal industry AI tools with plans to repeat this study annually and add others.Future iterations may expand to include more vendors additional tasks and coverage of international jurisdictions beyond the current U.S.focus. “There is growing momentum across the legal industry for standardized methodologies benchmarking and a shared language for evaluating AI tools,”the report notes. Nicola Shaver and Jeroen Plink of Legaltech Hub were credited for their “partnership in conceptualizing and designing the study and bringing together a high-quality cohort of vendors and law firms.” “Overall this study’s results support the conclusion that these legal AI tools have value for lawyers and law firms,”the study concludes“although there remains room for improvement in both how we evaluate these toolsand their performance.”



