
قياس الذكاء في الذكاء الاصطناعي: التحديات والمعايير الجديدة
الذكاء موجود في كل مكان، ومع ذلك يبدو أن قياسه أمرٌ ذاتي. في أفضل الأحوال، نقوم بتقريب قياسه من خلال الاختبارات والمعايير. فكر في امتحانات القبول الجامعي: كل عام، يسجل عدد لا يحصى من الطلاب، ويحفظون حيل التحضير للاختبار وأحيانًا يحصلون على درجات كاملة. هل يعني رقم واحد، مثل 100%، أن الذين حصلوا عليه يتشاركون نفس مستوى الذكاء – أو أنهم قد بلغوا أقصى قدراتهم العقلية؟ بالطبع لا. المعايير هي تقريب وليس قياسات دقيقة لقدرات شخص ما – أو شيء ما – الحقيقية.
لقد اعتمدت مجتمع الذكاء الاصطناعي التوليدي لفترة طويلة على معايير مثل MMLU (فهم اللغة متعددة المهام الضخمة) لتقييم قدرات النماذج من خلال أسئلة اختيار من متعدد عبر تخصصات أكاديمية مختلفة. يتيح هذا التنسيق مقارنات مباشرة ولكنه يفشل في التقاط القدرات الذكية بشكل حقيقي.
على سبيل المثال، تحقق كل من Claude 3.5 Sonnet وGPT-4.5 درجات مشابهة على هذه المعيار. على الورق، يوحي هذا بقدرات متساوية. ومع ذلك، يعرف الأشخاص الذين يعملون مع هذه النماذج أن هناك اختلافات كبيرة في أدائها الفعلي.
ماذا يعني قياس “الذكاء” في الذكاء الاصطناعي؟
في أعقاب إصدار معيار ARC-AGI الجديد — وهو اختبار مصمم لدفع النماذج نحو التفكير العام وحل المشكلات الإبداعية — هناك نقاش متجدد حول ما يعنيه قياس “الذكاء” في الذكاء الاصطناعي. بينما لم يختبر الجميع معيار ARC-AGI بعد، فإن الصناعة ترحب بهذه الجهود وغيرها لتطوير أطر الاختبار. لكل معيار ميزته الخاصة ، ويعتبر ARC-AGI خطوة واعدة في تلك المحادثة الأوسع.
تطور آخر ملحوظ مؤخرًا في تقييم الذكاء الاصطناعي هو ”آخر امتحان للبشرية” ، وهو معيار شامل يحتوي على 3000 سؤال تمت مراجعتها من قبل الأقران عبر مجالات متنوعة متعددة الخطوات . بينما يمثل هذا الاختبار محاولة طموحة لتحدي نظم الذكاء الاصطناعي عند مستوى الخبرة ، تظهر النتائج الأولية تقدمًا سريعًا — حيث حققت OpenAI درجة تبلغ 26,6% بعد شهر واحد فقط من إصداره . ومع ذلك ، مثل المعايير التقليدية الأخرى ، فإنه يقيم أساسًا المعرفة والتفكير بمعزل عن بعضهما البعض دون اختبار القدرات العملية التي أصبحت أكثر أهمية للتطبيقات الواقعية للذكاء الاصطناعي .
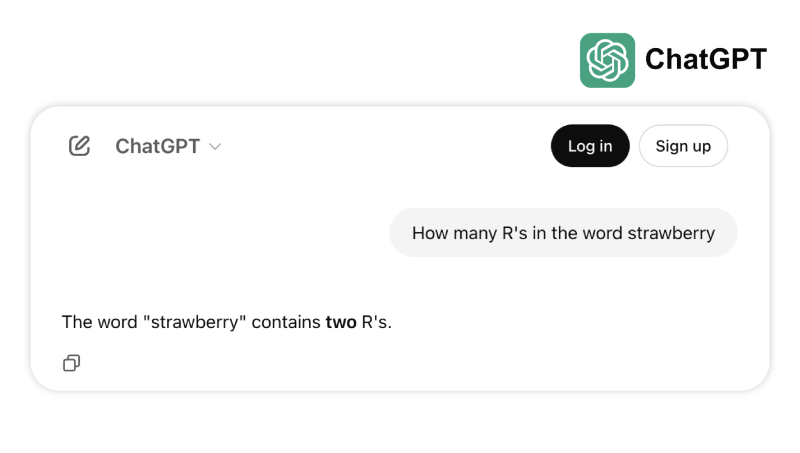
في أحد الأمثلة ، تفشل العديد من النماذج المتطورة بشكل كبير في العد الصحيح لعدد “r” الموجودين بكلمة “fراولة”. وفي مثال آخر ، تحدد خطأً الرقم 3,8 بأنه أصغر من الرقم 3,1111 . تكشف هذه الأنواع من الفشل — بشأن مهام يمكن حتى لطفل صغير أو آلة حاسبة بسيطة حلها — عن عدم تطابق بين التقدم المدفوع بالمعيار والصلابة الواقعية للعالم الحقيقي ، مما يذكرنا بأن الذكاء ليس مجرد اجتياز الامتحانات ولكن يتعلق بالتنقل بشكل موثوق عبر المنطق اليومي.
!Beyond ARC-AGI GAIA and the search for a real intelligence
المعيار الجديد لقياس قدرة الذكاء الاصطناعي
مع تقدم النماذج ، أظهرت هذه المعايير التقليدية حدودها – حيث حققت GPT-4 باستخدام الأدوات حوالي 15% فقط على المهام الأكثر تعقيداً والواقعية ضمن معيار GAIA، رغم الدرجات المثيرة للإعجاب التي حصلت عليها ضمن اختبارات اختيار متعدد .
أصبح هذا الانفصال بين أداء المعايير والقدرة العملية مشكلة متزايدة مع انتقال نظم ذكاءات اصطناعية إلى تطبيقات الأعمال . تختبر المعايير التقليدية استرجاع المعرفة لكنها تفوت جوانب مهمة للذكاء: القدرة على جمع المعلومات وتنفيذ التعليمات البرمجية وتحليل البيانات وتوليف الحلول عبر مجالات متعددة .
GAIA هو التحول المطلوب منهجيًّا لتقييم ذكاءات اصطناعية . تم إنشاؤه بالتعاون بين فرق Meta-FAIR وMeta-GenAI وHuggingFace وAutoGPT ويشمل المقياس 466 سؤالاً مصاغة بعناية عبر ثلاث مستويات صعوبة . تختبر هذه الأسئلة تصفح الويب والفهم متعدد الوسائط وتنفيذ التعليمات البرمجية والتعامل مع الملفات والتفكير المركب – وهي قدرات ضرورية للتطبيق العملي للذكاءات الإصطناعية .
تتطلب أسئلة المستوى الأول حوالي خمس خطوات وأداة واحدة لحلها البشر . تتطلب أسئلة المستوى الثاني خمس إلى عشر خطوات وعددًا متعددًا من الأدوات بينما يمكن أن تتطلب أسئلة المستوى الثالث ما يصل إلى خمسين خطوة منفصلة وأي عددٍ كانٍ للأدوات . يعكس هذا الهيكل التعقيد الفعلي لمشاكل الأعمال حيث نادرًا ما تأتي الحلول نتيجة إجراء واحد أو أداة واحدة .
من خلال إعطاء الأولوية للمرونة بدلاً عن التعقيد , حققت نموذج ذكائي دقة بنسبة %75 ضمن GAIA – متجاوزا عمالقة الصناعة Microsoft Magnetic–1 (38%) وGoogle Langfun Agent (49%). يعود نجاحهم إلى استخدام مزيجٍ خاصٍّ للنماذج لفهم الصوت والصورة والتفكير , مع نموذج Anthropic Sonnet 3,5 كنموذج رئيسي .
يعكس هذا التطور فى تقييم ذكاءات اصطناعيات تحولاً أوسع فى الصناعة : نحن ننتقل بعيداً عن تطبيقات SaaS المستقلة نحو وكلاءِ ذكاءات إصطنائية يمكنهم تنسيق أدوات متعددة وسير العمل المختلفة . ومع اعتماد الشركات بشكل متزايد على نظم ذكاءات إصطنائية للتعامل مع مهام مركبة ومتعددة الخطوات , توفر مقاييس مثل GAIA مقياسا أكثر معنىً للقدرة مقارنة باختبارات اختيار متعددة تقليدية .
يكمن مستقبل تقييم ذكاءات الإصطناعيات ليس فى اختبارات المعرفة المنعزلة بل فى تقييم شامل لقدرة حل المشكلات . تضع GAIA معيارا جديدا لقياس قدرة ذكيّ الإصطناعات – وهو الذي يعكس بشكل أفضل التحديات والفرص لنشر ذكيّ الإصطناعات بالعالم الحقيقي .
سري أمباتي هو مؤسس ومدير تنفيذي لشركة H2O.ai .




{kind=link}