إطلاق Llama 4: رد ميتا على DeepSeek مع نماذج Scout وMaverick وسرعة 2T من Behemoth في الطريق!

انضم إلى نشرتنا اليومية والأسبوعية للحصول على آخر التحديثات والمحتوى الحصري حول تغطية الذكاء الاصطناعي الرائدة في الصناعة. تعرف على المزيد
شهدت ساحة الذكاء الاصطناعي تحولًا كبيرًا في يناير 2025 بعد أن أطلقت شركة DeepSeek الصينية الناشئة (وهي فرع من شركة High-Flyer Capital Management التي تتخذ من هونغ كونغ مقرًا لها) نموذجها القوي للغة مفتوحة المصدر، DeepSeek R1، للجمهور، متفوقةً بذلك على أداء عمالقة التكنولوجيا الأمريكيين مثل ميتا.
مع انتشار استخدام DeepSeek بسرعة بين الباحثين والشركات، تم الإبلاغ عن أن ميتا دخلت في حالة من الذعر عند علمها بأن هذا النموذج الجديد R1 تم تدريبه بتكلفة ضئيلة مقارنة بالعديد من النماذج الرائدة الأخرى، حيث كانت التكلفة لا تتجاوز عدة ملايين من الدولارات — وهو ما تدفعه لبعض قادة فريق الذكاء الاصطناعي الخاص بها — ومع ذلك حقق أداءً ممتازًا في فئة المصادر المفتوحة.
كانت استراتيجية ميتا الكاملة للذكاء الاصطناعي التوليدي حتى تلك اللحظة تعتمد على إصدار نماذج مفتوحة المصدر الأفضل تحت اسم علامتها التجارية “لاما” ليتمكن الباحثون والشركات من البناء عليها بحرية (على الأقل إذا كان لديهم أقل من 700 مليون مستخدم شهري).
ومع ذلك، فإن الأداء المذهل لنموذج DeepSeek R1 بميزانية أصغر بكثير قد هز القيادة في الشركة وأجبرهم على مواجهة الواقع، حيث تم إصدار النسخة الأخيرة من لاما 3.3 قبل شهر فقط في ديسمبر 2024 لكنها بدت بالفعل قديمة.
الآن نعرف ثمار تلك المواجهة: اليوم blank” rel=”noreferrer noopener”>أعلن مؤسس ميتا ومديرها التنفيذي مارك زوكربيرغ عبر حسابه على إنستجرام عن blank” rel=”noreferrer noopener”>سلسلة جديدة من نماذج لاما 4، مع توفر اثنين منها – لاما 4 مافريك الذي يحتوي على 400 مليار معلمة ولما 4 سكوت الذي يحتوي على 109 مليار معلمة – اليوم للمطورين لتحميلها وبدء استخدامها أو تحسينها الآن عبر blank” rel=”noreferrer noopener”>llama.com ومجتمع مشاركة الأكواد AI blank” rel=”noreferrer noopener”>Hugging Face.
كما يتم عرض نموذج لاما 4 بيهموث الضخم الذي يحتوي على تريليوني معلمة اليوم أيضًا، رغم أن منشور مدونة ميتا حول الإصدارات ذكر أنه لا يزال قيد التدريب ولم يحدد موعد إصداره. (تذكر أن المعلمات تشير إلى الإعدادات التي تحكم سلوك النموذج وأن المزيد يعني عمومًا نموذج أقوى وأكثر تعقيدًا بشكل عام.)
إحدى الميزات الرئيسية لهذه النماذج هي أنها متعددة الوسائط - مدربة وقادرة بالتالي على استقبال وتوليد النصوص والفيديو والصور (لم يتم ذكر الصوت).
ميزة أخرى هي أنها تحتوي على نوافذ سياقية طويلة للغاية - مليون رمز لـ لاما 4 مافريك و10 ملايين لـ لاما 4 سكوت – وهو ما يعادل حوالي 1500 و15000 صفحة نصية تقريباً لكل منهما، وكل ذلك يمكن للنموذج التعامل معه في تفاعل إدخال/إخراج واحد. وهذا يعني أنه يمكن للمستخدم نظرياً تحميل أو لصق نص يصل إلى قيمة صفحات تصل إلى7500 صفحة واستلام نفس القدر كاستجابة من لاما 4 سكوت ، مما سيكون مفيداً لمجالات كثيفة المعلومات مثل الطب والعلوم والهندسة والرياضيات والأدب وغيرها.
إليك ما تعلمناه حتى الآن عن هذا الإصدار:
التركيز الكامل على خليط الخبراء
تستخدم جميع النماذج الثلاثة نهج “خليط الخبراء (MoE)” المعمارى الذي تم ترويجه في إصدارات سابقة للنماذج بواسطة OpenAI وMistral ، والذي يجمع أساساً بين عدة نماذج أصغر متخصصة (“خبراء”) في مهام مختلفة وموضوعات وصيغ وسائط ضمن نموذج موحد أكبر. يُقال إن كل إصدار لـ لاما 4 هو بالتالي خليط يتكون من128 خبير مختلف ، وأكثر كفاءة للتشغيل لأن الخبير المطلوب لمهمة معينة فقط هو الذي يتعامل مع كل رمز بدلاً عن تشغيل النموذج بالكامل لكل واحد منهم.
كما يشير منشور مدونة لاما:
نتيجة لذلك ، بينما يتم تخزين جميع المعلمات في الذاكرة ، يتم تنشيط مجموعة فرعية فقط من إجمالي المعلمات أثناء تقديم هذه النماذج. وهذا يحسن كفاءة الاستدلال عن طريق تقليل تكاليف خدمة النموذج وزمن الانتظار—يمكن تشغيل لاما 4 مافريك باستخدام مضيف [Nvidia] H100 DGX لتسهيل نشره أو باستخدام استدلال موزع لتحقيق أقصى قدر ممكن من الكفاءة.
كلٌّ مِن Scout ومافريك متاحان للجمهور للاستضافة الذاتية ، بينما لم يتم الإعلان عن أي واجهة برمجية مستضافة أو مستويات تسعير للبنية التحتية الرسمية لشركة ميتا. بدلاً عن ذلك ، تركز ميتا جهودها نحو توزيع التنزيل المفتوح والتكامل مع Meta AI داخل واتساب ومسنجر وإنستجرام والويب.
تقدر ميتا تكلفة الاستدلال لـلاما٤مافيك بـ $0.19 إلى $0.49 لكل مليون رمز (باستخدام نسبة خلط تبلغ3:1 للإدخال والإخراج). وهذا يجعل تكلفته أقل بكثير مقارنة بالنماذج الملكية مثل GPT-٤o والتي تُقدّر تكلفتها بـ$٤٫٣٨ لكل مليون رمز بناءً علي مقاييس المجتمع .
في الواقع, بعد فترة وجيزة جداً بعد نشر هذا المقال, تلقيت خبر بأن مزود استنتاج السحابة AI Groq قد قام بتمكين Llama٤Scout ومافريك بالأسعار التالية:
Llama٤Scout: $٠٫١١ / M رموز الإدخال و$٠٫٣٤ / M رموز الإخراج, بمعدل مختلط قدره $٠٫١٣
Llama٤مافيك: $٠٫٥٠ / M رموز الإدخال و$٠٫٧٧ / M رموز الإخراج, بمعدل مختلط قدره $٠٫٥٣
تم تصميم جميع نماذج Llama الأربعة—خصوصاً Maverick وBehemoth—بشكل صريح للتفكير والترميز وحل المشكلات خطوة بخطة — رغم أنهم لا يظهرون سلاسل التفكير الخاصة بنماذح التفكير المخصصة مثل سلسلة OpenAI “o” ولا DeepSeek R1 .
بدلاً عن ذلك يبدو أنهم مصممون للتنافس بشكل أكثر مباشرة مع نمادح “الكلاسيكية” غير المتعلقة بالتفكير والنمادح متعددة الوسائط مثل GPT-۴o الخاص بـOpenAI ونموذجات V3 الخاصة بـDeepSeek — باستثناء Llama۴Behemoth , والذي يبدو أنه يهددDeepSeekR۱(المزيد حول هذا أدناه!)
بالإضافة إلي ذالك , بالنسبة للـLlama۴ , قامتMeta ببناء خطوط أنابيب تدريب خاصة مركزة علي تعزيز التفكير,مثل:
- إزالة أكثر من 50% من “المطالبات السهلة” خلال عملية التعديل الدقيق تحت الإشراف.
- اعتماد حلقة تعلم تعزيز مستمرة مع مطالبات تتزايد صعوبتها تدريجياً.
- استخدام تقييم pass@k وعينة المنهج لتعزيز الأداء في الرياضيات والمنطق والترميز.
- تنفيذ تقنية MetaP الجديدة التي تتيح للمهندسين ضبط المعلمات الفائقة (مثل معدلات التعلم لكل طبقة) على النماذج وتطبيقها على أحجام وأنواع مختلفة من الرموز مع الحفاظ على سلوك النموذج المقصود.
تعتبر تقنية MetaP ذات أهمية خاصة لأنها يمكن أن تُستخدم في المستقبل لضبط المعلمات الفائقة على نموذج معين ثم الحصول على أنواع أخرى عديدة من النماذج، مما يزيد من كفاءة التدريب.
كما أشار زميلي في VentureBeat وخبير LLM بن ديكسون حول تقنية MetaP الجديدة: “يمكن أن يوفر هذا الكثير من الوقت والمال. يعني ذلك أنهم يقومون بإجراء التجارب على النماذج الأصغر بدلاً من القيام بها على النماذج الكبيرة.”
هذا أمر حاسم بشكل خاص عند تدريب نماذج بحجم Behemoth، التي تستخدم 32K وحدة معالجة رسومية ودقة FP8، محققة 390 TFLOPs لكل وحدة معالجة رسومية عبر أكثر من 30 تريليون رمز – وهو ما يزيد عن ضعف بيانات تدريب Llama 3.
بعبارة أخرى: يمكن للباحثين إخبار النموذج بشكل عام كيف يريدونه أن يتصرف، وتطبيق ذلك على النسخ الأكبر والأصغر للنموذج، وعبر أشكال مختلفة من الوسائط.
عائلة نماذج قوية – لكنها ليست بعد الأكثر قوة
في فيديو الإعلان الخاص به على إنستغرام(وهو فرع لشركة ميتا بالطبع)، قال مارك زوكربيرغ الرئيس التنفيذي لشركة ميتا إن “هدف الشركة هو بناء الذكاء الاصطناعي الرائد عالمياً، وفتحه كمصدر مفتوح وجعله متاحاً للجميع حتى يستفيد منه الجميع في العالم… لقد قلت منذ فترة إنني أعتقد أن الذكاء الاصطناعي المفتوح المصدر سيصبح النماذج الرائدة، ومع Llama 4 بدأ ذلك يحدث.”
إنها عبارة مصاغة بعناية واضحة كما هو الحال مع منشور مدونة ميتا الذي يصف Llama 4 Scout بأنه “أفضل نموذج متعدد الوسائط في العالم في فئته” وهو أقوى من جميع نماذج الجيل السابق لـLlama (التأكيد مني).
بعبارة أخرى، هذه نماذج قوية جداً، قريبة جداً إلى القمة مقارنةً بالآخرين في فئة حجم المعلمات الخاصة بهم ولكن ليس بالضرورة تسجل سجلات أداء جديدة. ومع ذلك ، كانت ميتا حريصةً للإعلان عن النماذج التي تتفوق عليها عائلة Llama 4 الجديدة ، ومن بينها:
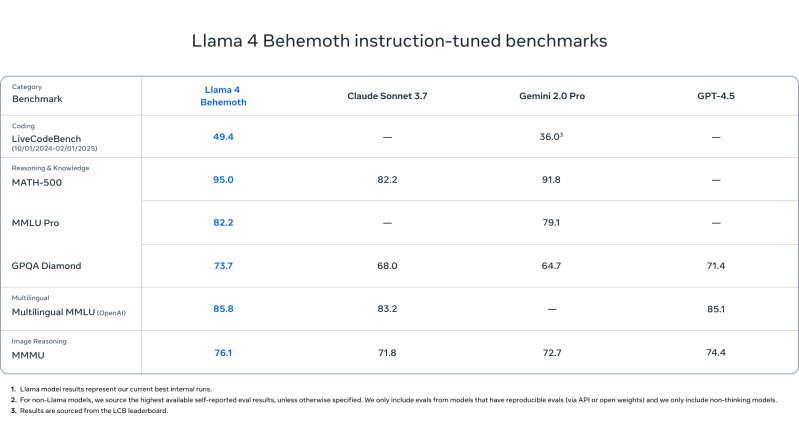
Llama 4 Behemoth
- - تتفوق على GPT-4.5 و Gemini 2.0 Pro و Claude Sonnet 3.7 في:
- MATH-500 (95.0)
- – GPQA Diamond (73.7)
- – MMLU Pro (82.2)
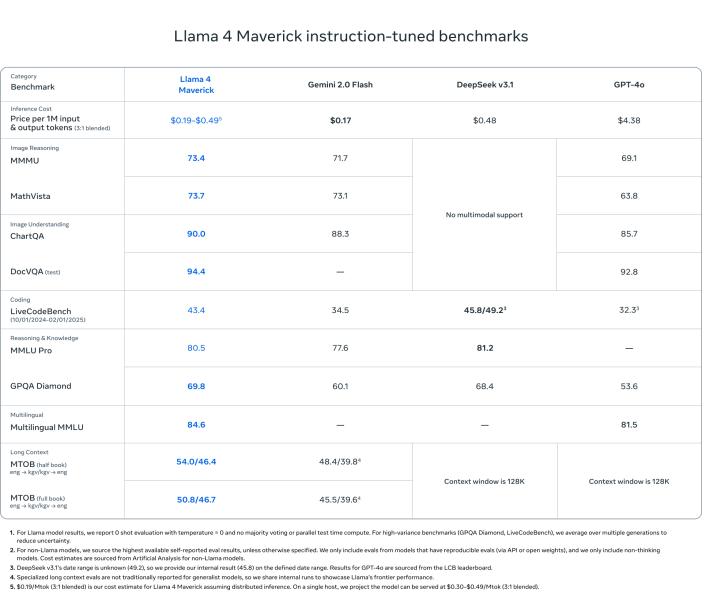
Llama 4 Maverick
- – تتفوق على GPT-4o و Gemini 2.0 Flash في معظم مؤشرات التفكير متعدد الوسائط:
- – ChartQA, DocVQA, MathVista, MMMU
- – تنافس DeepSeek v3.1 (45.8B params) بينما تستخدم أقل من نصف المعلمات الفعالة (17B)
- – درجات المؤشر:
- – ChartQA:90 .0( مقابل GPT -40’s85 .7 )
< li > – DocVQA :94 .( مقابل92 .8 )
< li > – MMLU Pro :80 .5
< li > - فعالة التكلفة :$19 – $49 لكل مليون رمز
L lama – scout “ < ulclass =" w p block list ">
< l i > تطابق أو تفوقعلى نماد ج مثلMistral–31 ,Gemini–20Flash Lite ,وGemma–03في :
< ulclass =" w p block list ">
< l i >Doc V QA :94 .( مقابل74 .)
< /l i >
< l i >MML UPro :74 .
< /l i >
< l i >Math Vista :70 .
< /l i >
< /u l > /
u l >
< figureclass ="w p block image size large is resized">< imgdecoding ="async" width = 1920height = 1359src= "https://alarabiya24news.com/wp-content/uploads/2025/04/ 1743947015_322_Metas-answer-to- DeepSeek-is-here-L lama - launches-with.png" alt="" class=" w p image3003438style= width:840px;height:auto"/>
لكن بعد كل هذا ، كيف تقارن لاما بـ Deep Seek؟
< p > لكن بالطبع هناك مجموعة كاملة أخرىمنالنموذجبالتركيزعلىالتفكيرمثلDeep Seek R1 وسلسلةOpenAI o مثلGPT-o.
< p > باستخدام أعلى نموذج تم اختباره بمعاملات عالية وهوL llama Behemoth ومقارنته بمخطط إصدار Deep Seek R1 الأولي لـR1-B32 ونموذجات OpenAI o1 إليكم كيفية مقارنة لاما بـBehemoth:
< figure class=" w p block table">
MATH-
500L llama Behemoth D eep S eek R1 P open AI o1217 MATH-
500.95 .97 .96 GPQA Diamond 73.7 71.5 75.7 MMLU 82.2 90.8 91.8 ماذا يمكن أن نستنتج؟
- MATH-500: لاما 4 بيهيموث متأخر قليلاً عن DeepSeek R1 و OpenAI o1.
- GPQA Diamond: بيهيموث متقدم على DeepSeek R1، لكنه متأخر عن OpenAI o1.
- MMLU: بيهيموث يتخلف عن كلاهما، لكنه لا يزال يتفوق على Gemini 2.0 Pro و GPT-4.5.
الاستنتاج: بينما تتفوق DeepSeek R1 و OpenAI o1 على بيهيموث في بعض المقاييس، تظل لاما 4 بيهيموث تنافسية للغاية وتؤدي عند أو بالقرب من قمة قائمة الأداء في فئتها.
السلامة وأقل تحيز سياسيٍّ
كما أكدت ميتا على توافق النموذج والسلامة من خلال تقديم أدوات مثل Llama Guard و Prompt Guard و CyberSecEval لمساعدة المطورين في اكتشاف المدخلات/المخرجات غير الآمنة أو المحفزات العدائية، وتنفيذ اختبار الوكلاء الهجومية التوليدية (GOAT) للاختبار الآلي للفريق الأحمر.
تدعي الشركة أيضًا أن لاما 4 يظهر تحسينًا كبيرًا في “التحيز السياسي”، وتقول “على وجه التحديد، [النماذج اللغوية الكبيرة الرائدة] تاريخيًا كانت تميل إلى اليسار عندما يتعلق الأمر بالمواضيع السياسية والاجتماعية المتنازع عليها”، وأن لاما 4 يؤدي بشكل أفضل في جذب اليمين… بما يتماشى مع احتضان زوكربيرغ للرئيس الجمهوري الأمريكي دونالد ج. ترامب وحزبه بعد انتخابات 2024.
أين تقف لاما 4 حتى الآن؟
مع توفر Scout و Maverick الآن للجمهور ومع عرض Behemoth كنموذج تعليمي متطور، فإن نظام لاما مستعد لتقديم بديل مفتوح تنافسي للنماذج المملوكة الرائدة من OpenAI و Anthropic و DeepSeek وجوجل.
زر الذهاب إلى الأعلى
- – ChartQA:90 .0( مقابل GPT -40’s85 .7 )